简单便捷的数据库版本管理工具:Flyway
简单便捷的数据库版本管理工具:Flyway
Bummon前言
首先在我们日常的工作中避免不了会出现客户/公司在原有项目上新增或修改功能的需求,而这些需求也往往伴随着数据库的更新。
当还在开发中的软件遇到此类情况倒是无所谓,但是很多时候是在我们的软件已经部署到客户服务器上,并且已经使用了一段时间,有了一部分的数据,我们不可能直接从数据库导出干净的数据库表给客户更新上。
当部署的软件比较多时,人工手动去改或者新增数据库的操作又过于繁琐。那么我们有没有更简单便捷的方式来帮助我们解决这样的问题呢?答案肯定是有的:Flyway
以上讲了这么多,那么究竟Flyway是什么呢?
Flyway是一个开源的数据库版本管理工具,其主要作用在于管理数据库的版本更新以及迭代,它能够自动化的将数据库的变更迁移到不同的数据库中,其也支持多种数据库类型,这里我们就用Java来集成Flyway实现我们想要的功能。
工作原理
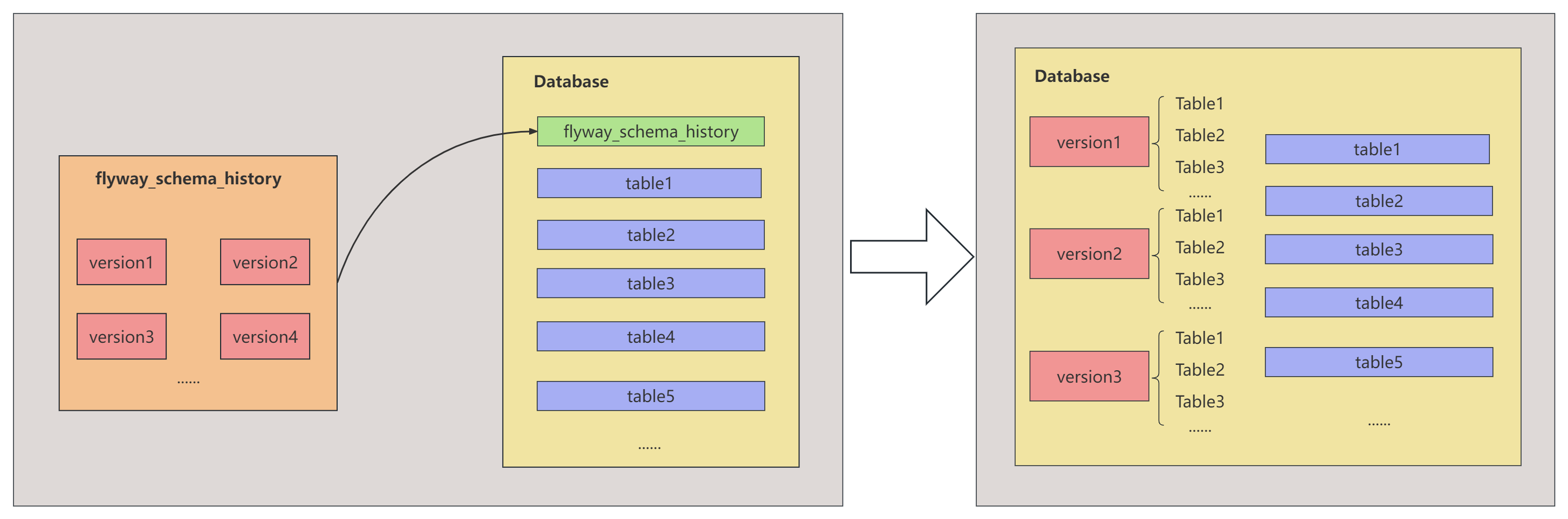
Flyway的工作原理非常简单,当你集成Flyway后,如果是初次启动,Flyway会在与你的数据库建立连接后自动的给你的数据库插入一个默认名为 flyway_schema_history 的表,这个表的主要作用就是来 保存Flyway的执行记录 。
Flyway在启动时也会扫描你设置的路径下的迁移SQL文件(默认路径为:classpath:db/migration ),并且与数据库中的 flyway_schema_history 中的数据进行比对,若迁移SQL文件与数据库中的记录不一致则会直接报错。当匹配成功后,Flyway会取出你的迁移文件,并忽略掉与历史执行记录表中匹配的迁移文件,按照版本大小依次执行你的迁移SQL。
Flyway提供了两种执行方式供我们选择,这也是我们使用Flyway必须要遵守的命名规则:
- 仅需要执行一次的迁移SQL:使用大写V开头,后跟版本号,并使用双下划线加上文件名或文件描述来命名( V版本号__文件描述.后缀名 ,如:V1__create_table.sql)
- 可重复多次执行的迁移SQL:使用大写R开头,后不跟版本号,直接使用双下划线进行分割,再跟上文件名或文件描述和后缀名( R__文件描述.后缀名 ,如:R__init_table.sql)
代码实现
首先我们要先集成Flyway的依赖
1 | <dependency> |
接着我们要配置我们的数据源
1 | spring: |
配置完数据源之后我们来写Flyway的配置文件,可以使用注入Config或YML和Properties的方式进行配置,在这里我们使用注入Config的方式来进行配置。
1 |
|
部分其他配置如下:
1 | # 对执行迁移时基准版本的描述 |
接下来我们在我们设置的路径下创建我们的迁移SQL
1 | CREATE TABLE test |
此时我们的数据库中是没有任何表的

最后我们启动项目来看一下
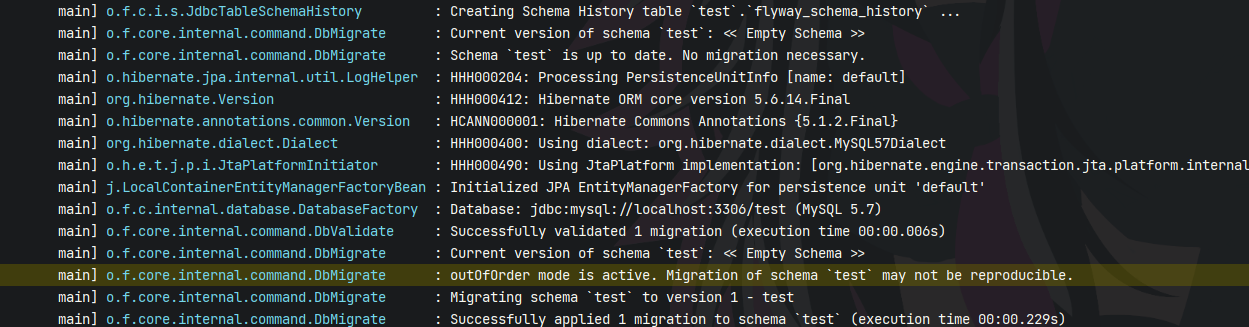
可以看到我们的控制台输出了这些内容,大致就是我们 Flyway 在执行迁移SQL时的一些输出,我们打开数据库看一眼,可以看到我们库中多了两张表:test 和 flyway_schema_history 。其中 test 表是我们迁移SQL中的数据,而 flyway_schema_history 则是我们 Flyway 执行的记录表。

我们打开这个表来看一下里面是什么。

这个表中包含了 installed_rank 、version 、description 、type 、script 、 checksum 、installed_by、insatlled_on 、execution_time 和 success 10个字段,我们分别来看一下他们都代表了什么。
- installed_rank :主键,没什么说的。
- version:我们迁移的版本,也就是我们V后面跟的版本号。
- type:执行迁移的类型,这里我们使用的是SQL。
- description:在双下划线后面写的描述,以上就是取的
V1__test.sql,就是取的test。 - script:我们执行文件的具体名称。
- checksum:校验字段,类似于唯一标识,用来对比我们库中的迁移SQL版本与我们库中已经执行的版本是否一致,若不一致会报错。
- installed_by:以哪个账户来迁移的该条SQL,我们可以在配置文件中指定,或使用主数据源。
- installed_on:执行迁移的时间。
- execution_time:执行迁移的时长。
- success:是否执行成功。
那么我们再试一下可重复执行的方式。
我们在同样的 sql 文件夹下创建一个迁移SQL,如下:
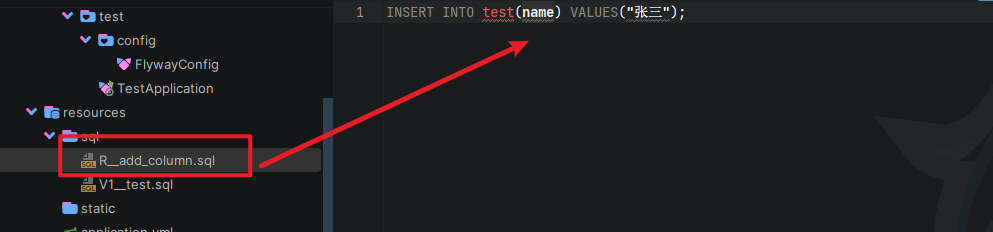
我们再来运行一下,发现输出日志如下:

也就是说,Flyway成功识别到我们R开头的迁移SQL并执行了,那我们再去 flyway_schema_history 去看一眼,如下:

发现其多了一条数据,我们再去test表看一眼:
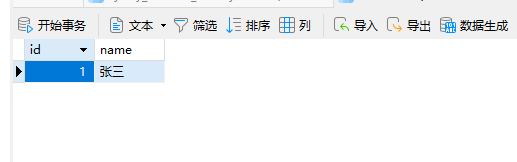
发现其确实多了张三的数据,那么我们在迁移的SQL中添加一句并重新启动试试:

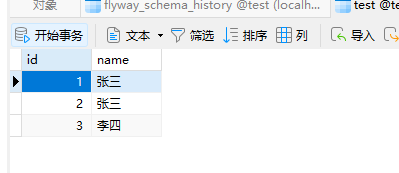
发现我们的可重复执行的迁移SQL也可以成功执行,至此结束。
总结
首先Flyway是一个数据库版本管理工具,其可以帮助我们便捷的管理数据库中的版本,并给我们提供了两种方式供我们选择:V(执行一次)和 R(可重复执行)。
在我们首次启动Flyway时,会自动向我们数据库插入一个默认名为 flyway_schema_history 的数据表,该表为存放Flyway执行记录的表。
V 和 R 的区别:
如果选择以 V 来作为迁移类型时,在项目启动时,先去 flyway_schema_history 表中查看该迁移数据的记录,若不存在该记录则执行该迁移SQL并向 flyway_schema_history 表中插入一条数据;若已存在迁移记录且唯一码一致时将不会执行迁移SQL;若已存在迁移记录,但唯一码不一致时会报错。
如果我们选择以 R 来作为迁移类型时,在项目启动时,同样会先去 flyway_schema_history 表中查看是否存在该迁移记录,若不存在则执行,若已存在且唯一码一致时不会执行,但若已存在且唯一码不一致时,会重新执行该迁移SQL并向 flyway_schema_history 中插入一条记录。